I got a job! I will be working at Mentimeter doing Data Engineering stuff!
There aren’t that many blog posts about looking for a job in Stockholm. I thought it would be fun to contribute by writing an After Action Report.
Background
I quit my job in June of 2022 to go traveling with my partner. We visited some cool places in Asia (Hiking in the Himalayas was a high point (🤓)). We were back in Sweden in early December. I then started sending out job applications.
I used this resume.
An executive summary of my resume would be:
- 2 years of experience
- Spark, Python & SQL
- Hadoop & GCP
- CI/CD and terraform stuff
I was only looking for roles based in Stockholm.
Screening
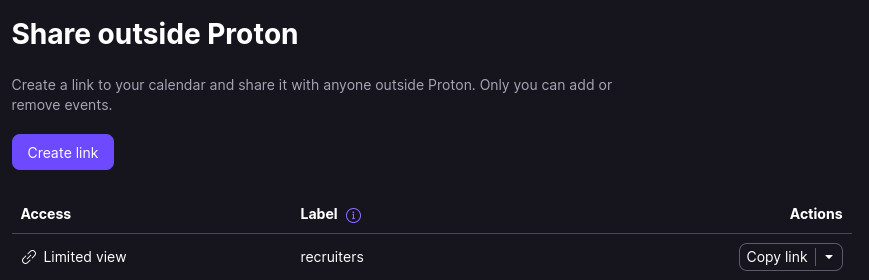
All processes started with a recruiter reaching out by email to schedule a phone call or a video meeting. In the beginning of my search it was easy to say yes to their proposed time, but after a week my calendar was quite full. I solved that by Publishing my calendar online
Most of the screenings was them telling me more about the role and the company. I also almost always got the question “Tell me a little about yourself”. And of course I got some time to ask questions about the company. I would recommend to have some questions ready!
Here are some reasons I withdrew:
- They had bad work-life balance (I’m very glad the recruiter was honest about it!)
- The product made didn’t make any sense (could just be me being stupid though!)
- They couldn’t bother to show up to our booked meetings, twice!

Technical
The majority of the technical interviews were take-homes. They were a Jupyter notebook (locally or Google Colab) with some data loaded. There were some tasks to do basic transformations, either in Python or in SQL. Then there was some basic system design questions, like “What would you do to fix a slow loading dashboard?”
One technical interview was just chatting with the hiring manager about technical stuff. Very pleasant experience!
For the live coding I had one in pure SQL and another in Python.
The Python one was similar to the take-homes with a jupyter notebook with some tasks. Just that I was doing it live with a time limit and also needed to talk through what I was doing.
I failed the SQL one, that’s on me for not preparing my SQL skills enough!
The live system design was a fun one, we started with some basic functionality. Then the interviewers started adding more and more requirements. I had to think about scale and cloud services for that one.
Cultural
I had two cultural interviews. They are quite personal, where you need to talk about how you handled situations at work.
I recommend breaking down a story into Situation, Task, Action, and Result. Called the STAR Method, famously used by Amazon for their behaviorals.
Offer
I got multiple offers and wanted to evaluate them all fairly. With the first few offers I asked for more time to finish the other processes. They were reluctant but agreed!
For me it’s also important who I’m working with. I arranged going to their office and meeting the team as well.
End
That’s it! If you have any other questions about the Data Engineering job market in Stockholm, shoot me an email at alex@dahl.dev :)
 Picture of the closing prices page on
Picture of the closing prices page on  The heat map of southern Sweden (where all the reasonable people live (sorry Norrland))
The heat map of southern Sweden (where all the reasonable people live (sorry Norrland))